Convert PDF to plain text
The following code sample shows how to convert the collection of glyphs on a PDF page to a text string. The algorithm detects spaces, line breaks and overlapping glyphs for visual effects.
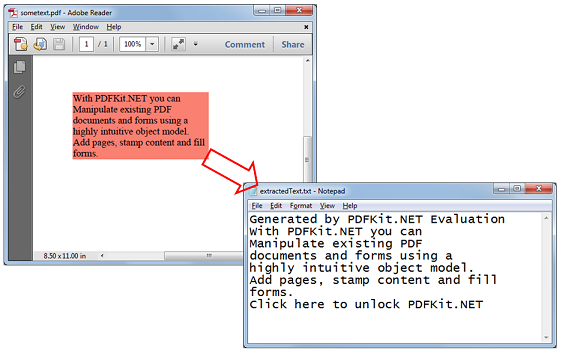
Code sample to convert PDF to plain text
using (FileStream fileIn = new FileStream(@"..\..\..\inputdocuments/sometext.pdf", FileMode.Open, FileAccess.Read))
{
Document document = new Document(fileIn);
//get the first page
Page page = document.Pages[0];
//retrieve all glyphs from the current page
//Notice that you grep a strong reference to the glyphs, otherwise the GC can decide to recycle.
GlyphCollection glyphs = page.Glyphs;
//default the glyph collection is ordered as they are present in the PDF file.
//we want them in reading order.
glyphs.Sort();
using (FileStream fileOut = new FileStream(@"..\..\extractedText.txt", FileMode.Create, FileAccess.Write))
{
StreamWriter writer = new StreamWriter(fileOut);
Glyph previousGlyph = null;
foreach (Glyph glyph in glyphs)
{
int spaces = CheckSpaces(previousGlyph, glyph);
for (int i = 0; i < spaces; i++)
{
//insert a space.
writer.Write(" ");
}
if (spaces == -1)
{
//insert an enter.
writer.WriteLine();
}
//insert the characters
foreach (char ch in glyph.Characters)
{
writer.Write(ch);
}
previousGlyph = glyph;
}
writer.Flush();
}
}
Using fileIn As New FileStream("..\..\..\inputdocuments/sometext.pdf", FileMode.Open, FileAccess.Read)
Dim document As New Document(fileIn)
'get the first page
Dim page As Page = document.Pages(0)
'retrieve all glyphs from the current page
'Notice that you grep a strong reference to the glyphs, otherwise the GC can decide to recycle.
Dim glyphs As GlyphCollection = page.Glyphs
'default the glyph collection is ordered as they are present in the PDF file.
'we want them in reading order.
glyphs.Sort()
Using fileOut As New FileStream("..\..\extractedText.txt", FileMode.Create, FileAccess.Write)
Dim writer As New StreamWriter(fileOut)
Dim previousGlyph As Glyph = Nothing
For Each glyph As Glyph In glyphs
Dim spaces As Integer = CheckSpaces(previousGlyph, glyph)
For i As Integer = 0 To spaces - 1
'insert a space.
writer.Write(" ")
Next
If spaces = -1 Then
'insert an enter.
writer.WriteLine()
End If
'insert the characters
For Each ch As Char In glyph.Characters
writer.Write(ch)
Next
previousGlyph = glyph
Next
writer.Flush()
End Using
End Using
//sometimes PDF files don't contain space characters, in this case words are not seperated like so: "word1 word2"
//but you have two Strings "word1" and "word2", where word2 is simply placed further away to simulate a " ".
//to account for this, we must check the positions of each Glyph which is why this function is necessary.
static int CheckSpaces(Glyph firstGlyph, Glyph secondGlyph)
{
if (firstGlyph == null)
{
//there is only 1 glyph to compare.
return 0;
}
if (firstGlyph.BottomLeft.Y != secondGlyph.BottomLeft.Y)
{
//they are not on the same line. (-1 will converted in an enter)
return -1;
}
double spaceBetween = secondGlyph.BottomLeft.X - firstGlyph.BottomRight.X;
if (spaceBetween < 0.1)
{
//[almost] overlapping text.
return 0;
}
double spaceLength = firstGlyph.Font.CalculateWidth(" ", firstGlyph.FontSize);
double spaces = spaceBetween / spaceLength;
return (int)Math.Round(spaces);
}
'sometimes PDF files don't contain space characters, in this case words are not seperated like so: "word1 word2"
'but you have two Strings "word1" and "word2", where word2 is simply placed further away to simulate a " ".
'to account for this, we must check the positions of each Glyph which is why this function is necessary.
Private Function CheckSpaces(firstGlyph As Glyph, secondGlyph As Glyph) As Integer
If firstGlyph Is Nothing Then
'there is only 1 glyph to compare.
Return 0
End If
If firstGlyph.BottomLeft.Y <> secondGlyph.BottomLeft.Y Then
'they are not on the same line. (-1 will converted in an enter)
Return -1
End If
Dim spaceBetween As Double = secondGlyph.BottomLeft.X - firstGlyph.BottomRight.X
If spaceBetween < 0.1 Then
'[almost] overlapping text.
Return 0
End If
Dim spaceLength As Double = firstGlyph.Font.CalculateWidth(" ", firstGlyph.FontSize)
Dim spaces As Double = spaceBetween / spaceLength
Return CInt(Math.Round(spaces))
End Function